In practice, however, Structuralists have proposed qualifiers that in effect extend the semantics of elements rather than just narrowing them. For example, they want to extend the Creator element to include an author's Affiliation. Such an extension could be very useful for customizing the Dublin Core for a particular local use. However, there are logical problems with this: an Affiliation is not a kind of Author; rather, an Affiliation is something an Author has. An uncontrolled proliferation of such qualifiers would muddy the semantics of Dublin Core. And since Web harvesters are unlikely to recognize all of these qualifiers, they would either have to ignore any qualified elements (and not index Affiliation) or else go ahead and index Affiliations as if they were names of Creators. In either case, the precision of retrieval would suffer. We will return below to this problem with sub-structure.
So one might take the Dublin Core in English as the canonical version and simply prepare translations in multiple languages. This has already been done for German and Thai.[13,14] And there are precedents for this among the library standards. The guidelines for Universal Standard Bibliographic Description (USBD) are available in many translations. Universal Decimal Classification (UDC) and Dewey Decimal Classification (DDC), which aim at achieving multilingual universality through their language-neutral, numerical notations, have both been translated into many languages --- thirty for DDC, which is used in 135 countries. However, such systems must continually be revised as new knowledge develops. And in practice, this means revising a canonical version, usually in English, and accepting lengthy delays while translations are prepared.
This paper argues that this need not be the model for making Dublin Core operational across multiple languages. Rather than treat local instantiations of Dublin Core in multiple languages as mere translations of a canonical version (``Dublin Core with Sub-Titles''), one could treat them as equal participants in an ongoing process of collective negotiation and revision.
Theologians of the day liked to speculate about the divine dialect mankind had shared before the Tower of Babel and about the iconic, almost telepathic communion of angels. Plans were devised whereby mankind once again might praise God in a single tongue. There was much interest in musical notation, numerals, shorthand, and ideograms, which seemed to encode universal concepts independently of language. The languages that resulted from such considerations often used invented symbols or notation. Some were based on comprehensive taxonomies and precise rules, the better to reflect the orderliness of creation. Most were designed to be written, though some could also be pronounced.
John Wilkins (1668) arranged ``all things and notions'' in a large chart under forty main headings, according to which each thing and notion was assigned an artificial word; the spelling of his word for dog reflected its position under beast, viviparous, rapacious, and dog-like.[15] George Dalgarno's philosophical language (1661) differentiated the meanings of artificial words by altering vowels and inserting consonants according to complex rules.
Missionaries returning from Asia reported that speakers of Mandarin and Cantonese could not understand each other's speech, yet shared a common script, which also was used extensively in Korea, Vietnam, and Japan. The notion took root that ``ideographs'' could convey ideas directly to speakers of totally unrelated languages, much like the arabic numeral 3 is immediately understandable to a Russian and a Spaniard. (This misconception has been soundly refuted --- Chinese characters are basically phonetic and thus no more universal than the Latinate roots shared by European languages.[3])
The urge to create languages a priori did not survive as a movement beyond the seventeenth century, though related proposals have appeared sporadically since then. A ``universal musical language'' of the early nineteenth century, Solresol, constructed word semantics with sequences of diatonic notes that could be whistled, played, or spoken. More recently, Lincos (1960) was devised for ``cosmic intercourse'' with intelligent life in distant galaxies. And Margaret Mead (1968) called on scholars to create a language-neutral script for communicating high-level scientific concepts.[10] In a general sense, one might see formal logic notation, Macintosh icons, signage at airports and sporting events, scientific nomenclature, thesauri, and the composite codes of Dewey decimal classification as direct or spiritual descendants of this movement.
The first proposal to achieve much success was Volap\"uk or ``World Speak'' (1879), a German priest's creative synthesis of German, English, and Latin. Morphologically complex, Volap\"uk had over half a million possible verb forms. Its decline in popularity coincided with the rise of Esperanto (1887), a simpler language with a more Slavic flavor to its syntax and spelling. The decades that followed saw the creation of many more such languages -- several of them modifications of Esperanto, such as Ido (1907), and Novial (1928).
Instead of inventing artificial languages, others tried to simplify the grammar and vocabularies of existing natural languages. Kolonialdeutsch (1916) was intended to be sufficient for German masters giving orders to ``natives,'' but not complete enough to allow the latter to eavesdrop or debate among themselves. Basic English (1930) offered a list of 850 English words --- short enough to be printed ``on a single sheet of business notepaper'' yet long enough to express all the ``root ideas'' needed for practical communication. Its author proposed to promote its use through phonograph records and International Basic News on the radio.
The a posteriori languages were a bit more flexible and adaptable. Most were created by a single author, working in isolation, then adopted by a small circle of followers. As the movements grew, early users had noisy disagreements about whether to accommodate new words or constructions. Debates often reflected the conflicting requirements of the everyday needs of speakers versus the demands of specialists. The Volap\"uk movement split over a conflict between, in effect, Minimalists and Structuralists: its inventor, Johann Martin Schleyer, wanted Volap\"uk to express the full range of semantic distinctions of natural languages, while some of his followers wanted to simplify it so as to improve its chances of adoption as an international auxiliary. The Esperanto movement, founded by the Polish philologist Ludwik Lejzer Zamenhof, likewise argued over issues such as its use of the circumflex, and factions broke off to promote alternative versions. Umberto Eco concludes that ``Such seems to be the fate of artificial languages: the `word' remains pure only if it does not spread; if it spreads, it becomes the property of the community of its proselytes, and (since the best is the enemy of the good) the result is `Babelization'.''[4]
Artificial languages never succeeded in getting the support of a government, though the United Nations briefly considered adopting Esperanto. Die-hard exponents of Esperanto still believe that its best chances lie in marketing it only as an auxiliary language, promoting its use in mass media, and forming an international supervisory association to maintain standards, review proposals, and control the language's evolution. As Eco points out, past failures do not mean there will be no attempt to find political consensus for such an auxiliary in the future. Were this to happen, he speculates, success would depend on instituting control from above, though not so tightly as to stifle the auxiliary language's capacity to express new everyday experiences.[9]
One would then need to resolve just how the institutional control from above would relate to the natural change in usage from below. Two scholars of ``language engineering,'' Donald Laycock and Peter M\"uhlh\"ausler, suggest the path to an answer. Natural languages, they point out, are versatile and open-ended, whereas most invented languages were designed as closed, rather strictly governed by rules, lacking in ``linguistic naturalness,'' and ill-suited to change. To achieve success, they argue, language designers should provide for peoples' propensity to change or create rules, adapt systems, and negotiate meanings. And to make progress along these lines, they conclude, language engineers need to examine how communities of users interact spontaneously to create pidgins.[8]
Steven Pinker, a linguist in the Chomskian tradition, cites an example. After 1979, the new Sandanista government in Nicaragua created special schools for the country's deaf students. Between classes on lip-reading, the ten-year-old children invented a pidgin sign language on the playground. But when younger pupils, aged four and older, learned this pidgin from their elders, they came to sign more fluently and efficiently. It appears that the younger children improvised and standardized a sign language creole. Pinker concludes that, as with other artificial languages created by theoreticians, ``Educators [...] have tried to invent sign systems, sometimes based on the surrounding spoken language. But these crude codes are always unlearnable, and when deaf children learn from them at all, they do so by converting them into much richer natural languages.''[12]
This process of complexification is not always just the work of children. Tok Pisin is a well-documented example of a pidgin that has become stabilized and extended without undergoing full creolization. Over the past century, it has become a lingua franca to about 1.5 million people and is the primary language of debate in the parliament of Papua New Guinea.
However, the process of proposing, refining, and elaborating Dublin Core has been significantly different than for Volap\"uk and Esperanto. Unlike Schleyer and Zamenhof, Stuart Weibel has defined his role less as inventor than as facilitator of a process. That process has benefitted from the unprecedented availability of email, Web sites for shared drafts, mailing lists, and cheap air travel to sustain the interaction of several dozen scholars and practitioners and hundreds more interested observers in negotiating the emerging standard.
At one of the early workshops, Ricky Erway defined Dublin Core as a phrase book for the ``virtual tourist'' who needs to browse collections in unfamiliar fields. The metaphor is especially apt because tourists are inclined to pidginize. Dublin Core is like a set of pidgin metadata elements created by natives of different user communities. One might carry the analogy a step further and suggest that the customization of Dublin Core with qualifiers for specific user communities represents its creolization. Or if creolization is too strong a word, since it implies the action of an inbuilt bioprogram for language acquisition, one might speak at least of the pidgin's stabilization and extension, as with Tok Pisin.
Either way, real pidgins are living languages that continually evolve through use in public speech and the mass media. If pidgin metadata is not to be constrained too tightly by its own rules from evolving naturally, it will need a mechanism that supports such collective, ongoing negotiation. This mechanism could resemble an interlingua.
To integrate these wordnets into a single system, EuroWordNet considered linking them all pair-wise. However, this would have multiplied work by the number of languages to be linked, making it hard to scale up to additional languages and a nightmare to maintain. They also considered linking all of the other monolingual wordnets to the English wordnet. However, the lexical configurations and semantic scopes specific to the various languages would have been lost in trying to map them onto any one of the languages. For example, the Italian word dito refers to both fingers and toes. No one language incorporates the subtleties of all the others.
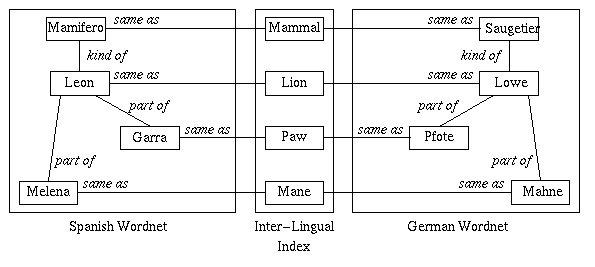
Rather, they decided to link the monolingual wordnets to an interlingua --- a flat, unstructured superset of concepts found in all of the languages. Words are linked to the closest meanings in the interlingua via shared equivalence or near-equivalence relations. Figure 1 illustrates that lions are mammals, and lions have paws and mane. The Dutch, Spanish, English, and French words for mammal, lion, paw, and mane are established as synonyms of each other through their parallel links to the respective concepts in the interlingua.
Within the interlingua, these concepts are not linked semantically among themselves, for their positions in language-specific lexical configurations may differ; no such links could do equal justice to all languages. This design maintains the richness and diversity of the various languages within their respective wordnets, while supporting some useful semantic fuzziness in the links between them (for example, dito is linked to fingers, toes, and fingers-and-toes).
But where would this leave Generic Harvesters? Global services of the Alta Vista sort will probably not want to program their indexing robots to process all of the sub-structure that people will build into their Dublin Core metadata. Would they index T. Baker, baker@gmd.de, Prof., and 1957 all together under Creator? This would pollute the Creator element with undifferentiated email addresses, birthdates, affiliations, and terms of rank. Or would they index only the Author --- one of the top ten most popular qualifiers, let's suppose --- and ignore the rest? In the absence of simple conventions to make such distinctions, Dublin Core metadata could become quite messy.
This is not unlike a procedure suggested by John Kunze for managing the evolution of Dublin Core.[7] Kunze envisioned a canonical Core, along with a mechanism for announcing local or experimental extensions and a formal review and approval process for accepting them into the canon. Maintainers of the Core would need to examine proposed additions for overlap and conflict with existing sub-elements. As in EuroWordNet, related terms of significantly different scope could be registered in the interlingua side-by-side. Their multiple definitions would appear as alternates, as in a natural language dictionary. The interlingua would consist of a stable base of approved elements surrounded by an evolving set of elements in less formal use. All implementers of Dublin Core in whatever form or language could participate by posting or proposing new sub-elements.
This process could be overseen by something like the Usage Panel of the American Heritage Dictionary, whose 173 writers, critics, and scholars help its editors find a balance between descriptions of actual usage and prescriptions of preferred forms, while evaluating potential entries against ``the fundamental linguistic virtues --- order, clarity, and conciseness.''[11]
Unless the Dublin Core community were to adopt some language-neutral way to express element names, such as the numbers of Dewey Decimal Classification, it would seem expedient to follow EuroWordNet in using English. The glosses for concepts in EuroWordNet's interlingua read like English dictionary definitions, such as a finger-like part of vertebrates, or any substance that can be metabolized.
And in the absence of convincing implementations of, say, SGML tags in multiple languages, it seems practical to name the sub-elements in English too. Or if the Web's future Resource Description Framework were to support it, perhaps elements could be identified with both a universal name (its Dublin Core name, in English) and a local name in the local language. This way, designers of local systems could invent element names for local uses independently of Dublin Core, then fill in the blanks for universal names as matches to Dublin Core were identified.[1]
Such questions will be resolved in the marketplace of practice. The interlingua could constitute this market's forum --- both a reference model for users and harvesters and the locus of ongoing evolution.
[2]David Crystal. Artificial languages. In: The Cambridge Encyclopedia of Language. Cambridge (Eng): Cambridge University Press, pp. 352-356, 1987.
[3]John DeFrancis, The Chinese Language: Fact and Fantasy. Honolulu: University of Hawaii Press, 1984, p. 159.
[4]Umberto Eco. The Search for the Perfect Language. Oxford: Blackwell, 1995, pp. 319, 346.
[5]Joseph H. Greenberg. A New Invitation to Linguistics. Garden City (NY): Anchor Books, 1977, pp. 57, 126.
[6]Jon Knight and Martin Hamilton. Dublin Core Qualifiers, ROADS Project, Department of Computer Studies, Loughborough University, http://www.roads.lut.ac.uk/Metadata/DC-Qualifiers.html, 1997.
[7]John Kunze. A Unified Element Vocabulary for Metadata. http://www.ckm.ucsf.edu/personnel/jak/dist.html, 1996.
[8]Donald C. Laycock and Peter M\"uhlh\"ausler. Language Engineering: Special Languages. In: An Encyclopaedia of Language. London: Routledge, pp. 843-875, 1994, p. 871.
[9]Andr\'e Martinet, 1991. Cited in Eco, p. 332.
[10]Margaret Mead and Rudolf Modley, 1968. Cited in De Francis, p. 164.
[11]Geoffrey Nunberg. Usage in the American Heritage Dictionary: the Place of Criticism. In: The American Heritage Dictionary of the English Language, Third Edition. Boston: Houghton Mifflin Company, Pp. xxvi-xxx, 1992.
[12]Steven Pinker. The Language Instinct. New York: Harper Collins, 1994, p. 36.
[13]Diann Rusch-Feja. Dublin Core Version 1.0 in German. http://www.mpib-berlin.mpg.de/DOK/metatagd.htm, 1996.
[14]Praditta Siripan. Dublin Core in Thai. National Science and Technology Development Agency, Bangkok, Thailand, 1997.
[15]J.L. Subbiondo. Universal Language Schemes in Seventeenth-Century Britain. In: Encyclopedia of Language and Linguistics, Vol. 9, pp. 4841-4845, Oxford: Pergamon, 1994.
[16]Piek Vossen, Pedro Diez-Orzas, Wim Peters. Multilingual design of EuroWordNet. http://www.let.uva.nl/~ewn/Vossen.ps, 1997.
[17]Stuart Weibel, Renato Iannella, Warwick Cathro. The 4th Dublin Core Metadata Workshop Report. D-Lib Magazine, June 1997, http://www.dlib.org/dlib/june97/metadata/06weibel.html, 1997.
{kind=link}